أصبحت الحدود بين ما هو حقيقي وما هو غير حقيقي أقل من أي وقت مضى بفضل أداة الذكاء الاصطناعي الجديدة من Microsoft.
تعمل هذه التقنية، التي يطلق عليها VASA-1، على تحويل الصورة الثابتة لوجه الشخص إلى مقطع متحرك له وهو يتحدث أو يغني.
وتزعم شركة التكنولوجيا العملاقة أن حركات الشفاه “متزامنة بشكل رائع” مع الصوت لجعل الأمر يبدو وكأن الموضوع قد أصبح واقعًا.
في أحد الأمثلة، تبدأ تحفة ليوناردو دافنشي في القرن السادس عشر “الموناليزا” في موسيقى الراب بشكل فظ بلكنة أمريكية.
ومع ذلك، تعترف مايكروسوفت بأنه من الممكن “إساءة استخدام” الأداة لانتحال هوية البشر، ولم تطلقها للعامة.

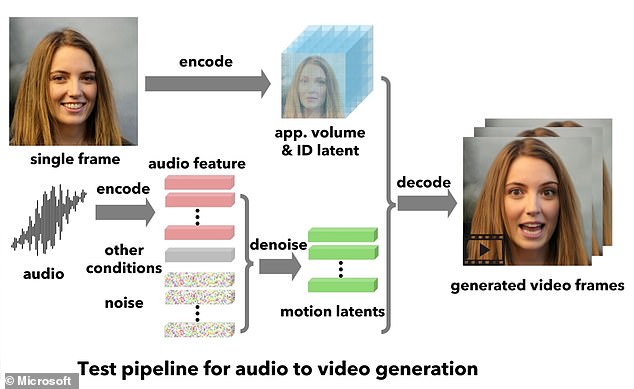
يمكن لأداة VASA-1 الجديدة من Microsoft إنشاء مقاطع لأشخاص يتحدثون من صورة ثابتة وصوت لشخص يتحدث – لكن عملاق التكنولوجيا لن يطلقها في أي وقت قريب
يلتقط VASA-1 صورة ثابتة للوجه – سواء كانت صورة لشخص حقيقي أو عمل فني أو رسم لشخص خيالي.
ثم يقوم بعد ذلك بمطابقة ذلك “بدقة” مع صوت الكلام “من أي شخص” لإضفاء الحيوية على الوجه.
تم تدريب الذكاء الاصطناعي باستخدام مكتبة من تعبيرات الوجه، والتي تتيح له أيضًا تحريك الصورة الثابتة حتى في الوقت الفعلي – حتى يتم نطق الصوت.
وفي منشور بالمدونة، وصف باحثو مايكروسوفت VASA بأنه “إطار عمل لإنشاء وجوه ناطقة واقعية لشخصيات افتراضية”.
ويقولون: “إنه يمهد الطريق لتفاعلات في الوقت الفعلي مع صور رمزية نابضة بالحياة تحاكي سلوكيات المحادثة البشرية”.
“طريقتنا ليست قادرة على إنتاج تزامن ثمين بين الشفاه والصوت فحسب، بل يمكنها أيضًا التقاط مجموعة كبيرة من المشاعر والفروق الدقيقة المعبرة في الوجه وحركات الرأس الطبيعية التي تساهم في إدراك الواقعية والحيوية.”
فيما يتعلق بحالات الاستخدام، يعتقد الفريق أن VASA-1 يمكن أن يمكّن الصور الرمزية الرقمية للذكاء الاصطناعي من “التفاعل معنا بطرق طبيعية وبديهية مثل التفاعلات مع البشر الحقيقيين”.
لكن الخبراء عبروا عن مخاوفهم بشأن هذه التكنولوجيا، والتي إذا تم إطلاقها قد تجعل الناس يبدون وكأنهم يقولون أشياء لم يقولوها أبدًا.
يتطلب VASA-1 صورة ثابتة للوجه – سواء كانت صورة لشخص حقيقي أو عمل فني أو رسم لشخص وهمي. إنه يطابق ذلك “بدقة” مع صوت الكلام “من أي شخص” لإضفاء الحيوية على الوجه

قال فريق Microsoft إن VASA-1 “ليس المقصود منه إنشاء محتوى يستخدم للتضليل أو الخداع”
هناك خطر محتمل آخر وهو الاحتيال، حيث يمكن خداع الأشخاص عبر الإنترنت من خلال رسالة مزيفة من صورة شخص يثقون به.
وقال جيك مور، المتخصص الأمني في شركة ESET، “الرؤية لم تعد تصدق بعد الآن”.
وقال لـ MailOnline: “مع تحسن هذه التكنولوجيا، أصبح هناك سباق مع الزمن للتأكد من أن الجميع يدركون تمامًا ما هو قادر، وأنه يجب عليهم التفكير مرتين قبل قبول المراسلات على أنها حقيقية”.
وتوقعًا للمخاوف التي قد تكون لدى الجمهور، قال خبراء مايكروسوفت إن VASA-1 “ليس المقصود منه إنشاء محتوى يستخدم للتضليل أو الخداع”.
ويضيفون: “ومع ذلك، مثل تقنيات إنشاء المحتوى الأخرى ذات الصلة، لا يزال من المحتمل إساءة استخدامها لانتحال شخصية البشر”.
“نحن نعارض أي سلوك لإنشاء محتويات مضللة أو ضارة لأشخاص حقيقيين، ونحن مهتمون بتطبيق أسلوبنا لتعزيز اكتشاف التزوير.”
“في الوقت الحالي، لا تزال مقاطع الفيديو التي تم إنشاؤها بهذه الطريقة تحتوي على قطع أثرية يمكن التعرف عليها، ويظهر التحليل الرقمي أنه لا تزال هناك فجوة لتحقيق صحة مقاطع الفيديو الحقيقية.”
تعترف مايكروسوفت بأن التقنيات الحالية لا تزال بعيدة عن “تحقيق صحة الوجوه الناطقة الطبيعية”، لكن قدرة الذكاء الاصطناعي تنمو بسرعة.

وبغض النظر عن الوجه الموجود في الصورة، يمكن للأداة تكوين تعبيرات وجه واقعية تتوافق مع أصوات الكلمات التي يتم نطقها
وفقاً للباحثين في الجامعة الوطنية الأسترالية، فإن الوجوه المزيفة التي يصنعها الذكاء الاصطناعي تبدو أكثر واقعية من الوجوه البشرية.
وحذر هؤلاء الخبراء من أن تصوير الذكاء الاصطناعي للأشخاص يميل إلى “الواقعية المفرطة”، مع وجوه أكثر تناسبًا، ويخطئ الناس في ذلك باعتباره علامة على الإنسانية.
وجدت دراسة أخرى أجراها خبراء في جامعة لانكستر أن وجوه الذكاء الاصطناعي المزيفة تبدو أكثر جدارة بالثقة، مما له آثار على الخصوصية عبر الإنترنت.
وفي الوقت نفسه، قدمت OpenAI، مبتكر روبوت ChatGPT الشهير، أداة تحويل النص إلى فيديو “المرعبة” Sora في فبراير، والتي يمكنها إنشاء مقاطع فيديو AI واقعية للغاية تعتمد فقط على مطالبات نصية وصفية قصيرة.

هذا الإطار لمقطع فيديو تم إنشاؤه بواسطة الذكاء الاصطناعي لطوكيو والذي أنشأه Sora من OpenAI صدم الخبراء بواقعيته “المرعبة”

ردًا على سؤال “قطة توقظ صاحبها النائم وتطالبه بالإفطار”، أعاد سورا هذا الفيلم
تحتوي صفحة مخصصة على موقع OpenAI على معرض غني لأفلام الذكاء الاصطناعي، بدءًا من رجل يمشي على جهاز المشي إلى انعكاسات في نوافذ قطار متحرك وقطة توقظ صاحبها.
ومع ذلك، حذر الخبراء من أنها قد تقضي على صناعات بأكملها مثل إنتاج الأفلام وتؤدي إلى ارتفاع مقاطع الفيديو المزيفة العميقة التي تسبق الانتخابات الرئاسية الأمريكية.
وقال الدكتور أندرو روجويسكي من جامعة سري: “إن فكرة أن الذكاء الاصطناعي يمكنه إنشاء مقطع فيديو شديد الواقعية، على سبيل المثال، لسياسي يفعل شيئًا غير مرغوب فيه، يجب أن تدق أجراس الإنذار مع دخولنا في العام الأكثر ازدحامًا بالانتخابات في تاريخ البشرية”. .
تم نشر ورقة بحثية تصف أداة Microsoft الجديدة كنسخة أولية.